- Published on
🧠 Khám phá AI #7: Giải thích về Phân cụm K-Means
- Authors

- Name
- Nguyễn Văn Lộc
- @vanloc1808
🧠 Khám phá AI #7: Giải thích về Phân cụm K-Means
K-Means là một trong những thuật toán được sử dụng rộng rãi nhất cho phân cụm không giám sát. Nó phân chia dữ liệu thành K nhóm riêng biệt dựa trên độ tương tự, mà không cần bất kỳ nhãn nào.
Trong bài viết này, bạn sẽ học K-Means là gì, nó hoạt động như thế nào, toán học đằng sau nó, cách chọn K, và cách triển khai nó trong Python.
🧩 K-Means là gì?
Phân cụm K-Means nhằm mục đích nhóm các điểm dữ liệu thành K cụm sao cho mỗi điểm thuộc về cụm có trung bình (centroid) gần nhất.
🧠 K-Means hoạt động như thế nào (Từng bước)
- Khởi tạo K centroid một cách ngẫu nhiên
- Gán mỗi điểm cho centroid gần nhất
- Cập nhật centroid bằng cách tính trung bình của các điểm trong mỗi cụm
- Lặp lại bước 2–3 cho đến khi hội tụ (việc gán không thay đổi)
Mục tiêu là giảm thiểu phương sai trong cụm (hoặc tổng bình phương trong cụm).
🧮 Hàm mục tiêu
Thuật toán K-Means giảm thiểu loss sau:
Trong đó:
- là tập hợp các điểm trong cụm
- là centroid của cụm
📉 Chọn K: Phương pháp Elbow
Số lượng cụm là một siêu tham số.
Để chọn , bạn có thể:
- Vẽ inertia (tổng khoảng cách bình phương đến centroid gần nhất)
- Tìm kiếm một "điểm elbow" nơi lợi ích của việc thêm nhiều cụm hơn giảm đi
Hình ảnh dưới đây cho thấy "điểm elbow" nơi lợi ích của việc thêm nhiều cụm hơn giảm đi.
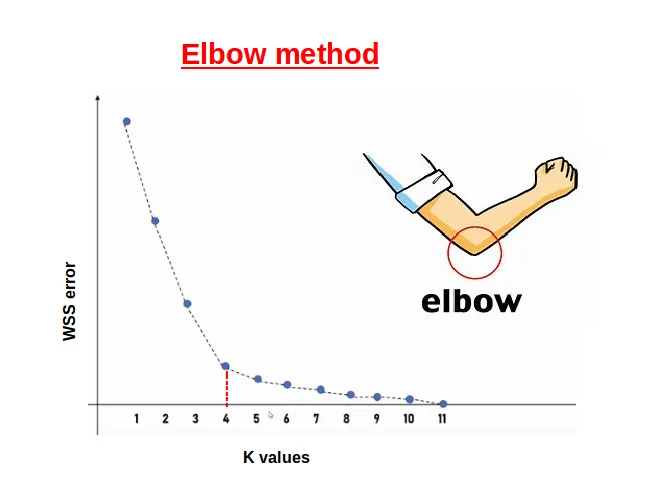
Hình: Điểm elbow nơi lợi ích của việc thêm nhiều cụm hơn giảm đi. Nguồn: Medium
🧪 Ví dụ mã: Phân cụm dữ liệu Iris với K-Means
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 📥 Tải dữ liệu Iris
iris = load_iris()
X = iris.data
labels = iris.target
features = iris.feature_names
# 🔍 Áp dụng phân cụm KMeans
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(X)
# 📊 Trực quan hóa các cụm
df = pd.DataFrame(X, columns=features)
df['Cluster'] = clusters
sns.pairplot(df, hue='Cluster', palette='Set2', corner=True)
plt.suptitle('Phân cụm K-Means trên tập dữ liệu Iris', y=1.02)
plt.tight_layout()
plt.show()
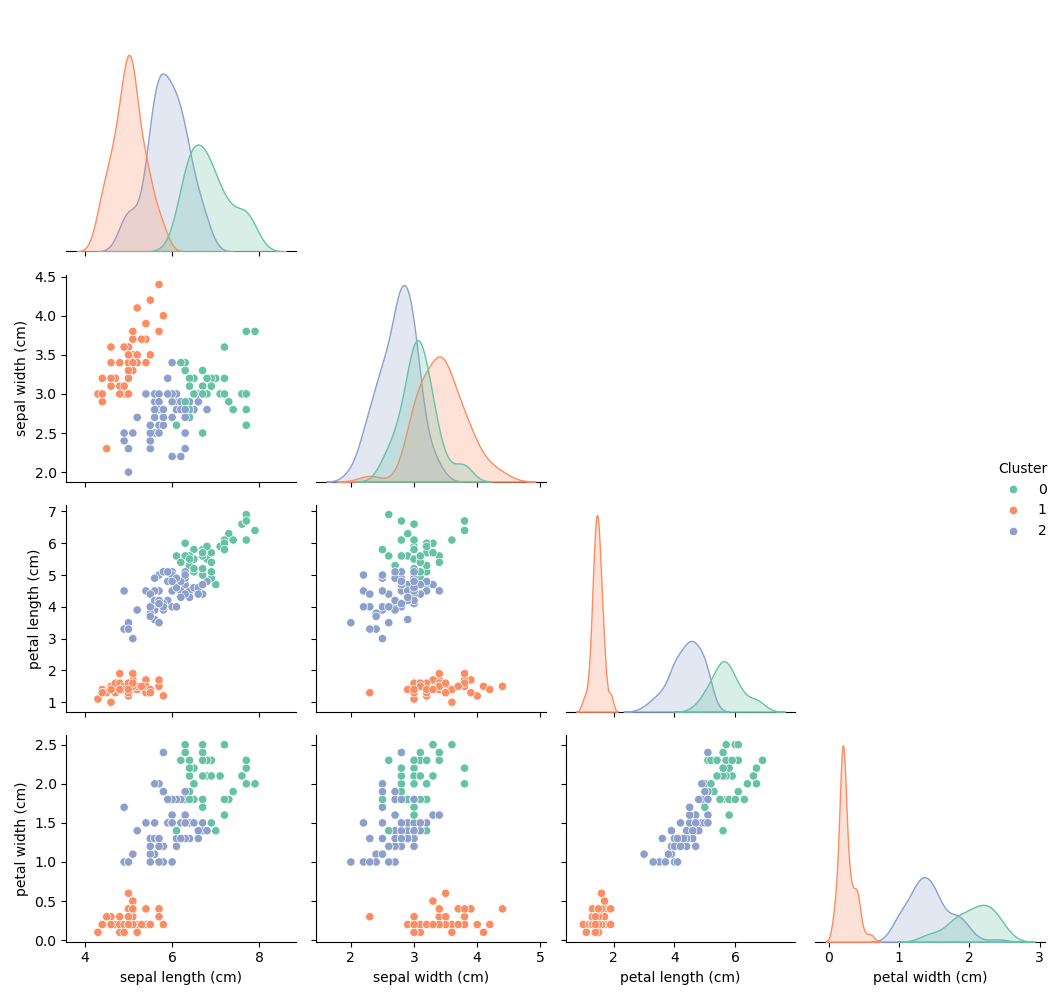
Ví dụ này phân cụm tập dữ liệu Iris thành 3 nhóm mà không sử dụng nhãn loài thực — cho thấy sức mạnh của học không giám sát trong việc khám phá cấu trúc.
📊 Biểu đồ pair plot dưới đây cho thấy K-Means đã phân cụm tập dữ liệu Iris thành ba nhóm riêng biệt dựa trên độ tương tự đặc trưng — mà không sử dụng nhãn loài thực. Đáng chú ý, các cụm căn chỉnh tốt với loài thực tế, đặc biệt khi chiều dài cánh hoa và chiều rộng cánh hoa được liên quan, cho thấy sức mạnh của học không giám sát trong việc khám phá cấu trúc tự nhiên.
📈 Dọc theo đường chéo, mỗi subplot là một biểu đồ KDE (Kernel Density Estimate), trực quan hóa cách các giá trị của một đặc trưng cụ thể được phân phối trong mỗi cụm:
- Mỗi đường cong màu đại diện cho một cụm (ví dụ: Cụm 0, 1, hoặc 2).
- Trục x là giá trị đặc trưng (ví dụ: chiều rộng cánh hoa), trong khi trục y là mật độ ước tính.
- Các đỉnh trong biểu đồ KDE cho thấy nơi các điểm dữ liệu tập trung — giúp bạn thấy đặc trưng nào tách biệt các cụm tốt nhất.
- Nếu các đường cong KDE được tách biệt rõ ràng, đặc trưng đó đóng góp mạnh mẽ vào việc phân cụm.
✅ Ưu và nhược điểm
✅ Ưu điểm
- Đơn giản, nhanh, và dễ triển khai
- Hoạt động tốt khi các cụm có hình cầu và được phân tách rõ
- Mở rộng cho các tập dữ liệu lớn
❌ Nhược điểm
- Phải chỉ định K trước
- Nhạy cảm với khởi tạo (có thể hội tụ đến cực tiểu cục bộ)
- Gặp khó khăn với hình dạng cụm không đều hoặc không hình cầu
📊 Khi nào sử dụng K-Means
Sử dụng K-Means khi:
- Bạn muốn phân cụm nhanh, có thể mở rộng
- Bạn có ý tưởng sơ bộ về số lượng cụm tồn tại
- Dữ liệu của bạn có phương sai tương đối đồng đều
🔚 Tóm tắt
K-Means là một thuật toán phù hợp cho nhiều vấn đề phân cụm. Mặc dù đơn giản, nó mạnh mẽ khi được áp dụng cho đúng loại dữ liệu và cung cấp một điểm khởi đầu tuyệt vời cho các tác vụ học không giám sát.
🔜 Tiếp theo
Tiếp theo trong loạt phụ này về kỹ thuật phân cụm: DBSCAN — một phương pháp dựa trên mật độ để khám phá các cụm có hình dạng tùy ý và phát hiện outlier.
Hãy tò mò và tiếp tục khám phá 👇
🙏 Lời cảm ơn
Cảm ơn ChatGPT đã cải thiện bài viết này với các gợi ý, định dạng và biểu tượng cảm xúc.