- Published on
🧠 Khám phá AI #5: Phân loại trong Học có giám sát
- Authors

- Name
- Nguyễn Văn Lộc
- @vanloc1808
🧠 Khám phá AI #5: Phân loại trong Học có giám sát
Phân loại là một nhánh chính của học có giám sát tập trung vào việc dự đoán các danh mục hoặc nhãn lớp. Cho dù bạn đang xây dựng bộ phát hiện thư rác hay bộ phân loại bệnh, phân loại có ở khắp mọi nơi.
Trong bài viết này, chúng ta sẽ khám phá cách phân loại hoạt động, các thuật toán phổ biến, hàm mất mát, thước đo đánh giá, và một ví dụ mã thực tế.
🧠 Phân loại là gì?
Phân loại là một tác vụ học có giám sát trong đó mục tiêu là gán đầu vào cho một trong số nhiều danh mục rời rạc.
Ngược lại với hồi quy (dự đoán giá trị liên tục), phân loại xuất ra các nhãn như
thư rác/không phải thư rác,mèo/chó, hoặctích cực/tiêu cực.
📦 Ví dụ thực tế: Phát hiện thư rác Email
- Đầu vào (X): Nội dung văn bản email, người gửi, dòng chủ đề
- Đầu ra (Y): Nhãn (
Thư ráchoặcKhông phải thư rác) - Mô hình học từ hàng nghìn email có nhãn để xác định các mẫu thư rác.
🧪 Các loại phân loại
| Loại | Mô tả | Ví dụ |
|---|---|---|
| Phân loại nhị phân | Hai lớp có thể | Phát hiện thư rác, khối u: lành tính/ác tính |
| Phân loại đa lớp | Nhiều hơn hai lớp | Nhận diện chữ số (0–9), loại động vật |
| Phân loại đa nhãn | Gán nhiều nhãn cho một thể hiện | Gắn thẻ bài viết với nhiều chủ đề |
🔑 Các thuật toán phổ biến
| Thuật toán | Mô tả | Tốt nhất cho |
|---|---|---|
| Hồi quy Logistic | Bộ phân loại tuyến tính cho nhị phân/đa lớp | Văn bản, dữ liệu dạng bảng |
| Cây quyết định | Phân chia dựa trên cây theo đặc trưng | Mô hình có thể giải thích |
| Rừng ngẫu nhiên | Tập hợp các cây | Tác vụ đa lớp mạnh mẽ |
| Naive Bayes | Mô hình xác suất | Lọc thư rác, phân tích cảm xúc |
| k-NN | Phân loại dựa trên láng giềng gần nhất | Tập dữ liệu nhỏ |
| SVM | Tìm lề tối ưu giữa các lớp | Dữ liệu nhiều chiều |
| Mạng nơ-ron | Mô hình sâu cho dữ liệu phức tạp | Hình ảnh, âm thanh, văn bản |
📉 Hàm mất mát
🔹 Mất mát Cross-Entropy (Log Loss)
Cho phân loại nhị phân:
Cho đa lớp:
Điều này phạt các dự đoán tự tin nhưng không chính xác nặng hơn.
📊 Thước đo đánh giá
| Thước đo | Trường hợp sử dụng | Ghi chú |
|---|---|---|
| Độ chính xác | Tính đúng tổng thể | Tốt cho tập dữ liệu cân bằng |
| Độ chính xác | Trong số dự đoán tích cực, có bao nhiêu đúng | Quan trọng để giảm false positive |
| Độ nhớ | Trong số tích cực thực tế, có bao nhiêu được tìm thấy | Quan trọng để bắt tất cả tích cực |
| Điểm F1 | Trung bình điều hòa của độ chính xác và độ nhớ | Tốt nhất khi các lớp không cân bằng |
| Ma trận nhầm lẫn | Cái nhìn chi tiết về TP, FP, FN, TN | Tuyệt vời cho chẩn đoán đa lớp |
🧪 Ví dụ mã: Phân loại loài hoa Iris
Chúng ta sẽ sử dụng tập dữ liệu Iris cổ điển để phân loại loài hoa bằng LogisticRegression.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
# 🌸 Tải tập dữ liệu Iris
data = load_iris()
X = data.data
y = data.target
class_names = data.target_names
# 🔀 Chia train-test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 🧠 Huấn luyện bộ phân loại
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 📈 Đưa ra dự đoán
y_pred = model.predict(X_test)
# 📊 Đánh giá
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# 🖼️ Lưu biểu đồ ma trận nhầm lẫn
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6, 5))
sns.heatmap(
cm,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=class_names,
yticklabels=class_names,
)
plt.xlabel("Dự đoán")
plt.ylabel("Thực tế")
plt.title("Ma trận nhầm lẫn - Phân loại Iris")
plt.tight_layout()
plt.savefig("iris_confusion_matrix.png")
📊 Ma trận nhầm lẫn dưới đây (đạt được sau khi chạy mã) cho thấy mô hình đã phân loại chính xác tất cả các mẫu kiểm tra trên cả ba lớp (
setosa,versicolor,virginica). Điều này cho thấy hiệu suất xuất sắc trên tập dữ liệu Iris, không có phân loại sai nào.
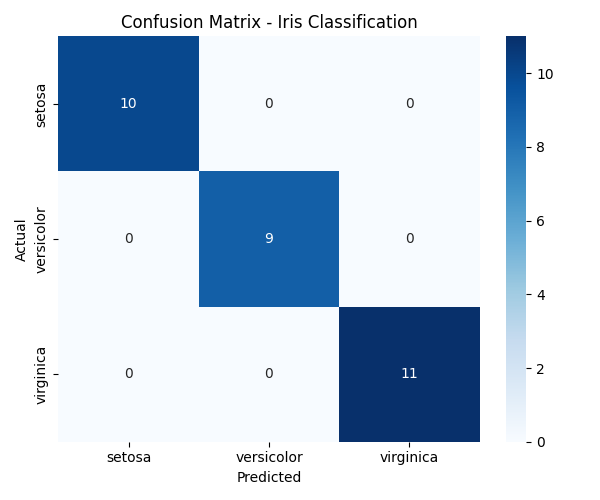
Ví dụ này cho thấy việc huấn luyện một bộ phân loại đa lớp và đo độ chính xác, độ nhớ, và điểm F1 đơn giản như thế nào.
✅ Khi nào sử dụng phân loại
- Khi đầu ra của bạn là một nhãn lớp
- Khi bạn đang giải quyết các vấn đề như chẩn đoán, phát hiện gian lận, gắn thẻ, hoặc nhận diện
- Khi độ chính xác, độ chính xác, hoặc độ nhớ có ý nghĩa hơn lỗi số thô
🔚 Tóm tắt
Phân loại là điều cần thiết để dạy máy móc cách nhận diện và gắn nhãn thế giới. Với các mô hình và thước đo đánh giá phù hợp, nó cung cấp sức mạnh cho vô số ứng dụng - từ sàng lọc y tế đến xử lý ngôn ngữ.
🔜 Tiếp theo
Trong bài viết tiếp theo, chúng ta sẽ khám phá Học không giám sát - nơi các mô hình học từ dữ liệu không có nhãn để tìm các cấu trúc ẩn.
Hãy tò mò và tiếp tục khám phá 👇
🙏 Lời cảm ơn
Cảm ơn ChatGPT đã cải thiện bài viết này với các gợi ý, định dạng và biểu tượng cảm xúc.